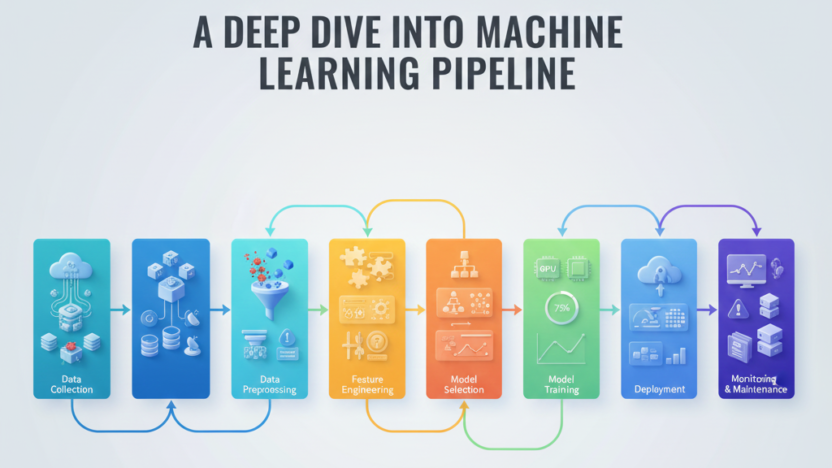
The machine learning pipeline is the foundation of successful AI development. It guides teams from raw data to fully deployed models. This blog looks at each important stage: data collection, preprocessing, feature engineering, model training, evaluation, and deployment. It also highlights best practices that ensure effectiveness, scalability, and long-term reliability.
It discusses how automation, MLOps, and continuous monitoring improve performance and lower risks in production environments. Whether you’re new to the field or have experience, this deep dive provides valuable insights into creating efficient ML workflows and understanding how structured pipelines drive innovation across industries.
Table of Contents
- Introduction
- Why Machine Learning Pipelines Matter
- Data Collection and Acquisition
- Data Cleaning and Preprocessing
- Exploratory Data Analysis (EDA)
- Feature Engineering and Selection
- Model Selection and Training
- Model Evaluation and Validation
- Hyperparameter Tuning and Optimization
- Model Deployment Strategies
- Automation and MLOps in Modern ML Pipelines
- Conclusion
1. Introduction
Machine learning (ML) has quickly grown from a niche research area into a vital technology behind many modern applications. It impacts everything from personalized recommendations and fraud detection to healthcare diagnostics and self-driving vehicles. As businesses increasingly depend on ML-driven solutions, it is essential to understand how these systems are built, trained, deployed, and maintained, just as much as it is important to know what they can accomplish.
At the core of every ML solution is the machine learning pipeline, a structured process that ensures data progress through the right stages efficiently, models are built properly, and predictions are reliable in real-world situations. A pipeline is not just a list of tasks; it is a framework designed to provide consistency, scalability, reproducibility, and long-term reliability.
This blog offers an in-depth exploration of the entire machine learning pipeline, breaking down each important stage, including data collection and cleaning, feature engineering, model training, hyperparameter tuning, deployment, and ongoing operations through MLOps. Whether you are an aspiring data scientist, ML engineer, or professional wanting to better understand ML processes, this guide will provide useful insights into each step of the journey.
2. Why Machine Learning Pipelines Matter
ML pipelines serve as essential frameworks for producing models that are trustworthy, scalable, and maintainable. Without a pipeline, ML projects can become inconsistent, error-prone, and hard to reproduce.
1) Ensuring Reproducibility: An organized pipeline document and makes every step, algorithm, and transformation repeatable. Reproducibility is crucial in scientific research, business operations, and regulatory environments.
2) Improving Scalability: A pipeline allows ML systems to grow and handle larger datasets, increased demand, or more complex model structures.
3) Reducing Human Error: Automated and well-structured pipelines minimize mistakes like inconsistent preprocessing, mislabeled data, or model configuration errors.
4) Enhancing Collaboration: Standardized processes enable teams to work more efficiently. Data engineers, ML engineers, analysts, and stakeholders can collaborate more easily.
5) Streamlining Deployment: A well-organized pipeline makes it easier to transition from testing to real-world deployment, ensuring that models perform consistently in production.
6) Supporting Continuous Improvement: With pipelines, teams can quickly retrain models, update features, or integrate new data as business needs change.
In essence, ML pipelines turn machine learning from experimental, one-off projects into scalable and dependable production systems.
3. Data Collection and Acquisition
Data forms the foundation of every machine learning model. Without high-quality, relevant data, even the most sophisticated algorithms will struggle to deliver meaningful results. The data collection process involves identifying, sourcing, and curating datasets that accurately represent the problem being addressed.
1) Identifying Data Requirements
Before collecting data, it’s crucial to understand:
- What problem are we trying to solve?
- What data signals may be useful?
- How much data is needed?
- What are the data formats, frequencies, and constraints?
2) Types of Data Sources
Common sources include:
- Internal databases: CRM systems, transaction logs, operational data.
- External public datasets: Government portals, Kaggle, research datasets.
- APIs and web scraping: Real-time data collection from online platforms.
- IoT devices and sensors: Environmental data, telemetry, industrial IoT.
- User-generated data: User interactions, feedback, uploads.
3) Ethical and Legal Considerations
Responsible data acquisition requires compliance with:
- GDPR, CCPA, and other data privacy regulations.
- Ethical guidelines related to bias, consent, and transparency.
- Data anonymization and security best practices.
4) Data Volume and Variety
ML models often benefit from:
- Large amounts of data (big data challenges).
- A variety of data types, including structured (tables), semi-structured (JSON), and unstructured (images, audio, text).
- A thoughtful data collection strategy ensures that the dataset is representative, unbiased, and aligned with the final ML objectives.
4. Data Cleaning and Preprocessing
Raw data often needs preparation before modeling. It may contain inconsistencies, missing values, noise, duplicates, and irrelevant information. Data cleaning prepares raw data into a high-quality dataset that improves model training and accuracy.
1) Handling Missing Values
Common approaches include:
- Removal of incomplete rows.
- Imputation (mean, median, mode).
- Predictive imputation using ML methods.
- Domain-specific logic (e.g., filling with zero when appropriate).
2) Managing Outliers
Outliers can affect model performance:
- Z-score and IQR methods help identify anomalies.
- Outliers may be capped, transformed, or removed depending on the context.
3) Normalization and Standardization
Many ML algorithms rely on scaled numerical values:
- Normalization (Min-Max scaling) transforms values between 0 and 1.
- Standardization (Z-score scaling) centers values around mean = 0 and variance = 1.
4) Encoding Categorical Data
Techniques include:
- One-hot encoding.
- Label encoding.
- Target encoding.
- Embedding vectors (for large categories).
5) Text Preprocessing
For NLP tasks:
- Tokenization, stemming, and lemmatization.
- Removing stop words.
- Turning text into numerical vectors using TF-IDF or word embeddings.
6) Image and Audio Preprocessing
Includes:
- Resizing and normalization.
- Noise reduction.
- Spectrogram generation for audio.
- Data augmentation.
Clean, well-prepared data directly improves model performance and generalization.
5. Exploratory Data Analysis (EDA)
EDA is the process of exploring and visualizing data to discover patterns, correlations, outliers, and underlying structures before modeling. It helps guide decisions throughout the pipeline.
1) Understanding Data Distribution: Histograms, box plots, and density plots show how data spreads across features.
2) Identifying Relationships: Correlation matrices, scatter plots, and pair plots highlight connections between variables and possible predictive features.
3) Detecting Patterns
EDA can reveal seasonality, trends, or clusters that inform:
- Feature engineering.
- Model selection.
- Data transformations.
4) Identifying Bias or Skew
Skewed distributions may require:
- Log transforms.
- Synthetic data generation.
- Sampling techniques
5) Data Quality Assessment
EDA identifies:
- Missing data patterns.
- Noisy signals.
- Duplicated or inconsistent entries.
EDA lays a critical foundation for building strong ML models, allowing teams to make evidence-based decisions.
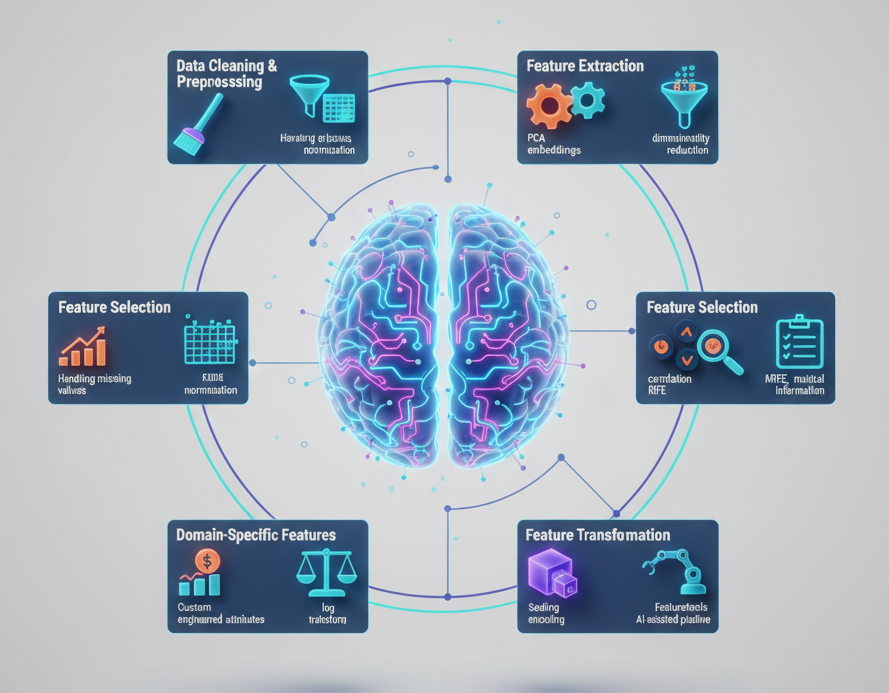
6. Feature Engineering and Selection
Features are the inputs for a machine learning model. Effective feature engineering often determines a model’s success or failure.
1) Creating New Features
Examples include:
- Aggregations (sum, mean, rolling windows).
- Ratios and differences.
- Polynomial features.
- Time-based features (lags, moving averages).
2) Transforming Existing Features: Log transforms, scaling, encoding, and binning enhance model sensitivity.
3) Selecting Relevant Features
Feature selection minimizes dimensionality and improves performance:
- Filter methods (correlation, chi-square).
- Wrapper methods (recursive feature elimination).
- Embedded methods (Lasso, tree-based importance).
4) Feature Importance Analysis
Tools like SHAP and LIME help explain:
- Which features matter most?
- How features impact predictions.
5) Domain Knowledge: Often, the best features come from domain expertise rather than automated tools.
Feature engineering is both an art and a science. It can significantly improve model accuracy.
7. Model Selection and Training
Once the data is prepared, the next step is to select the most suitable ML model.
1) Choosing the Right Algorithm
This depends on:
- Problem type (classification, regression, clustering).
- Data size.
- Feature complexity.
- Real-time needs.
2) Common Model Choices
- Linear Regression, Logistic Regression.
- Decision Trees and Random Forests.
- Gradient Boosting Machines (XGBoost, LightGBM).
- Support Vector Machines.
- Neural Networks (deep learning).
- Clustering algorithms (K-means, DBSCAN)
- Recommender systems.
3) Training the Model
Training involves feeding data through the algorithm to learn patterns:
- Split datasets into training, validation, and test sets.
- Use batch or mini-batch training for neural networks.
- Monitor loss functions.
4) Avoiding Overfitting
Techniques include:
- Regularization.
- Early stopping.
- Cross-validation.
- Dropout for neural networks.
Choosing and training the right model ensures predictions are accurate and generalizable.
8. Model Evaluation and Validation
Evaluating the model confirms it performs well not just on training data but also on unseen data.
1) Evaluation Metrics
Classification metrics:
- Accuracy, precision, recall, F1-score.
- ROC-AUC.
- Confusion matrix.
Regression metrics: RMSE, MAE, MAPE, R².
2) Cross-Validation: K-fold cross-validation offers a strong method to assess model generalization.
3) Bias and Variance Analysis
Understand whether the model suffers from:
- High bias (underfitting).
- High variance (overfitting).
4) Validation on Realistic Data
- Testing on real-world or time-split datasets is crucial for reliable performance.
- Model evaluation assures the model behaves as intended and performs reliably.
9. Hyperparameter Tuning and Optimization
Hyperparameters influence how an ML model learns. Tuning them can significantly enhance performance.
1) Tuning Techniques
- Grid search.
- Random search.
- Bayesian optimization.
- Genetic algorithms.
2) Hyperparameters Examples
- Learning rate.
- Tree depth.
- Number of estimators.
- Regularization strength.
- Dropout rate.
3) Automated Tuning: Tools like Optuna, Hyperopt, and AutoML simplify the optimization process.
4) Balance Between Computation and Performance
Excessive tuning can raise computational costs; finding the right balance is important.
Optimized hyperparameters can elevate models from “good” to “excellent.”
10. Model Deployment Strategies
Deployment is where models make a real-world impact.
1) Deployment Types
- Batch deployment: Predictions made regularly.
- Real-time deployment: API-based, immediate responses.
- Embedded deployment: Models integrated into devices (IoT, mobile apps).
2) Deployment Environments
- Cloud platforms (AWS, GCP, Azure).
- On-premise servers.
- Edge devices.
3) Ensuring Scalability: Containers (Docker), orchestration (Kubernetes), and autoscaling support large user bases.
4) Monitoring and Maintenance
Monitoring includes:
- Prediction accuracy.
- Latency.
- Model drift.
- Hardware utilization.
Deployment turns ML prototypes into functioning production systems.
11. Automation and MLOps in Modern ML Pipelines
MLOps combines machine learning with DevOps practices to streamline the entire lifecycle.
1) CI/CD for Machine Learning: Automatic retraining, testing, and deployment ensure consistent performance.
2) ML Pipeline Automation
Tools like Airflow, Kubeflow, MLflow, and Vertex AI automate:
- Data ingestion.
- Feature engineering.
- Training pipelines.
- Validation processes.
3) Tracking Experiments
MLflow, Weights & Biases (W&B), and Neptune track:
- Parameters
- Metrics
- Versions
- Artifacts
4) Model Governance: Ensures ethical, transparent, and accountable AI systems.
5) Continuous Monitoring
Detects:
- Model drift
- Data drift
- Performance decline
MLOps are crucial for scaling ML applications in modern businesses.
12. Conclusion
The machine learning pipeline is much more than a technical workflow. It is the backbone of modern AI development. From data collection and cleaning to feature engineering, model selection, deployment, and MLOps automation, every step contributes to the reliability and performance of machine learning systems.
Understanding this pipeline helps organizations and professionals create smarter, more scalable, responsible AI solutions. As machine learning continues to grow, pipelines will play an even more central role in ensuring that models are robust, interpretable, continuously improving, and capable of delivering real-world impact.


